Nicht ohne Grund !
Künstliche Intelligenz erkennt Muster schon lange viel besser als wir. Um aber ihren Namen wirklich zu verdienen, müsste sie auch kausale Zusammenhänge verstehen. Am Max-Planck-Institut für Intelligente Systeme in Tübingen arbeiten Forschende genau daran
Künstliche Intelligenz erkennt Muster schon lange viel besser als wir. Um aber ihren Namen wirklich zu verdienen, müsste sie auch kausale Zusammenhänge verstehen. Am Max-Planck-Institut für Intelligente Systeme in Tübingen arbeiten Forschende genau daran.


Text: Thomas Brandstetter
Ursache und Wirkung sind überall. Und nicht immer ist das ungleiche Paar so leicht zu erkennen wie beim Dominoeffekt, wo ein Stein den nächsten umstößt. So haben menschliche Entscheidungen oft sehr komplexe Ursachen – und mitunter noch komplexere Auswirkungen. Manchmal beeinflussen sich Dinge auch wechselseitig, etwa wenn unser CO2-Ausstoß die Erde erwärmt und auftauende Permafrostböden weiteres Treibhausgas freisetzen. Und wer ein idyllisches Landschaftsfoto betrachtet, sieht dabei in der Regel Schatten, die ihre Ursache im Licht der Sonne haben.
Während wir dank unseres Gehirns kausale Zusammenhänge meist intuitiv erkennen, bereiten diese unseren intelligenten Maschinen noch gehörige Schwierigkeiten. Die Maschinen mögen uns zwar im Auffinden von Mustern und Korrelationen übertreffen, das Konzept von Ursache und Wirkung bleibt ihnen aber in aller Regel verborgen. Die Wissenschaftlerinnen und Wissenschaftler der Abteilung für Empirische Inferenz am Max-Planck-Institut für Intelligente Systeme betrachten diese Unzulänglichkeit als Herausforderung. Unter der Leitung von Bernhard Schölkopf versuchen sie, lernenden Maschinen einen Sinn für Kausalität zu verleihen – und das in so unterschiedlichen Bereichen wie der Suche nach Exoplaneten, dem Klimawandel oder der Vergabe von Krediten.
Experimente bringen Verständnis
Ein Ansatzpunkt ihrer Arbeit ist die Qualität der zur Verfügung stehenden Daten. Die meisten Big-Data-Sätze entstehen aus rein passiver Beobachtung und enthalten keinerlei zusätzliche Informationen darüber, wie sie zustande gekommen sind. So sagen etwa Kontoumsätze, die nur die reinen Geldbeträge und die dazugehörigen Uhrzeiten beinhalten, nichts darüber aus, warum sie getätigt wurden. „Wenn ein System nur passiv Daten sammeln kann, reicht das gewöhnlich nicht aus, um einen kausalen Zusammenhang zu erkennen“, erklärt Julius von Kügelgen, der in der Abteilung für Empirische Inferenz an seiner Dissertation arbeitet. „Leider sind aber 99 Prozent der heute verfügbaren Daten rein passiv gesammelt oder werden zumindest in ihrer Auswertung so behandelt.“ Ein Beispiel dafür sind etwa statistische Daten, aus denen Zusammenhänge wie die Korrelation zwischen dem Schokoladekonsum pro Kopf und der Anzahl der gewonnenen Nobelpreise eines Landes abgeleitet werden können. In diesem Fall gilt das Common Cause Principle, das viele derartige Muster letztlich auf einen kausalen Zusammenhang zurückführt: Entweder beeinflusst eine Größe die andere, oder es gibt eine zusätzliche, dritte Variable, die beide kausal beeinflusst.
Die Korrelation selbst zu ermitteln, ist für eine Maschine ein Leichtes. Dazu muss der Algorithmus lediglich einschlägige Statistiken durchforsten und etwaige Muster erkennen. Um den Zusammenhang zu verstehen und eine mögliche Erklärung zu finden, braucht es aber zusätzliche Informationen. Uns Menschen hilft dabei in der Regel ein allgemeines Verständnis darüber, wie die Welt funktioniert. Wir haben schon Schokolade gegessen und wissen, dass sie keinen Einfluss auf die Intelligenz hat. Und weshalb sollte ein gewonnener Nobelpreis den Schokolade-konsum ankurbeln? Unsere Überlegungen werden also schnell in Richtung einer dritten Variablen gelenkt, etwa eines starken Wirtschaftssystems, das einerseits zu Wohlstand und Schokolade und andererseits zu einem guten Bildungssystem führt. Da aber einem Computeralgorithmus dieses allgemeine Verständnis fehlt, tappt er angesichts der bloßen Datenlage zwangsläufig im Dunkeln. „Interessanter sind da schon im Experiment gesammelte Daten, wo jemand aktiv in ein System eingreift und etwas verändert“, sagt von Kügelgen. Zum Beispiel zeigt zwar eine genaue Beobachtung schnell eine Korrelation zwischen nassem Boden und Regen auf. Doch ein Experiment, bei dem der Boden mit einem Gartenschlauch und nicht durch Regen nass gemacht wird, enttarnt den vermeintlichen kausalen Zusammenhang.

In seiner aktuellen Forschungsarbeit beschäftigt sich von Kügelgen allerdings mit noch schwierigeren Fällen. Ihn treiben Was-wäre-wenn-Fragen um, konkret etwa: Hätte ich den Kredit vielleicht doch bekommen, wenn mein Einkommen höher gewesen wäre? „Künstliche Intelligenz trifft immer öfter Entscheidungen für Menschen, etwa bei der Einschätzung von Kreditwürdigkeit“, sagt der Forscher. „Unser System kann den Leuten bei der Beantwortung der Frage helfen, was sie machen sollen, um ein positives Ergebnis zu erreichen.“ Dazu konstruiert er gemeinsam mit seinem Kollegen Amir Hossein Karimi Parallelwelten. Dort ist zwar vieles genauso wie in der echten Welt, es gibt aber auch Unterschiede wie etwa ein höheres Einkommen für eine bestimmte Person. Doch da dieser Unterschied nicht real ist, gibt es natürlich auch keine experimentellen Daten, die bei der Beantwortung der Was-wäre-wenn-Frage helfen könnten. Um abzuschätzen, wie die parallele Welt aussehen könnte, treffen die Forschenden also Annahmen darüber, wie sich die relevanten Variablen, die den Algorithmus zur Ablehnung des Kredits geführt haben, zueinander verhalten.
Üblicherweise sind es harte Fakten wie Einkommen, Alter und Ausbildung beziehungsweise Laufzeit und Höhe des beantragten Kredits, die über die Vergabe entscheiden. Dazu kommen noch zusätzliche Variablen, die zwar schwer messbar ist, den Entscheidungsprozess aber dennoch beeinflussen. Beispiele hierfür wären Faktoren wie der kulturelle Hintergrund oder das Charisma des Antragsstellers, die sich in den Algorithmus eingeschlichen haben. Sie werden als statistisches Rauschen zusammengefasst und müssen abgeschätzt werden. Im so entstandenen kausalen Modell lässt sich dann durchspielen, unter welchen Bedingungen eine Person den Kredit bekommen würde. Zu diesem Zweck wird jeweils eine Variable, etwa das Einkommen, verändert, während alle anderen Variablen gleich bleiben. „Schließlich sollte jeder in der Lage sein, durch einen gewissen persönlichen Aufwand seine Situation zu verbessern“, sagt von Kügelgen. „Dazu muss man aber erst einmal wissen, wie man gewisse Voraussetzungen am besten erfüllt. Und das können einem die bisher eingesetzten Algorithmen nicht sagen.“ Das zugrunde liegende kausale Modell, das beschreibt, wie die einzelnen Faktoren zusammenhängen, muss allerdings von einem Experten stammen. Ganz ohne einen Menschen, der Ahnung von der Sache hat, geht es also noch nicht. An der Kompetenz des Menschen, kausale Zusammenhänge zu verstehen, scheint also in absehbarer Zeit auch im maschinellen Lernen noch kein Weg vorbeizuführen. Und unsere kognitiven Fähigkeiten können natürlich als Vorbild für die Entwicklung intelligenter Maschinen dienen. „Unser Gehirn hat sich im Laufe der Evolution so entwickelt, dass es uns zu höchst kooperativen und sozial interaktiven Tieren gemacht hat“, sagt Martin Butz, der an der Universität Tübingen die Gruppe für Cognitive Modeling leitet. „Das erfordert in unterschiedlichen Situationen extrem flexibles Verhalten.“ Deshalb verfügen wir auch über eine interne Modellstruktur, die uns sagt, wie die Dinge in unserer Umgebung miteinander interagieren, welches kausale Prinzip hinter den Zusammenhängen steckt und welche Absichten unsere Mitmenschen antreiben. Als rein reaktive Roboter, die lediglich Muster erkennen und von der Aussicht auf Belohnungen angetrieben werden, wären wir dazu nicht in der Lage.
 und Amir Hossein Karimi entwickeln Modelle, die nachvollziehbare Entscheidungen über eine Kreditvergabe treffen.")

KI-Systeme wie Alpha Zero, ein Programm, das sich 2017 selbst das Schachspielen beigebracht hat, beweisen zwar, dass mit genug Trainingszeit und Rechenleistung auch ein reaktives System komplexes Verhalten lernen kann. Im Vergleich zu der Welt, in der sich Menschen zurechtfinden müssen, ist ein Spiel mit 32 Figuren auf 64 Feldern allerdings recht überschaubar. Außerdem mag Alpha Zero zwar besser spielen als ein Mensch, verstanden hat das Programm das Spiel aber nicht. Deshalb ist es auch nicht in der Lage, jemandem zu erklären, wie man Schach spielt. „Im Gegensatz dazu versucht unser Gehirn unentwegt, Zusammenhänge zu erklären“, sagt Butz. Schon Kleinkinder verstehen kausale Zusammenhänge sozialer Situationen intuitiv. So zeigen etwa entwicklungspsychologische Experimente, wie sie einem Erwachsenen, der einen Stapel Bücher trägt, zum Öffnen einer Tür zu Hilfe eilen. Sie erkennen also sowohl die Absicht des anderen, die Türe zu öffnen, als auch die Ursache für die Schwierigkeiten, nämlich die Bücher, aufgrund derer er keine Hand frei hat. Um in einer solchen Situation ähnlich kompetent zu reagieren, müssten Maschinen erst eine eigene Art interner Realität aufbauen, die nicht einfach nur immer wieder überschrieben wird, wenn man sie mit neuen Daten füttert. Sie müssten also in gewisser Weise ein konsistentes Verständnis der Welt ausbilden, wie es auch unserer Wahrnehmung zugrunde liegt. „Davon sind wir noch weit entfernt“, sagt Butz. „Andererseits gibt es aber auch keine Hinweise auf irgendeine Barriere, die es verhindern könnte, dass künstliche Systeme irgendwann menschliche Erkenntnisfähigkeit erreichen oder sogar übertreffen.“
Nicht nur soziale Interaktion und andere zeitliche Abläufe sind von Ursache und Wirkung geprägt, auch rein statische Darstellungen, etwa in Form von Fotografien, strotzen von kausalen Zusammenhängen. Sie stecken in den Mechanismen, die das Bild aufbauen, wie etwa der Perspektive, dem eingesetzten Licht und der Unterscheidung zwischen Vorder- und Hintergrund. Nur wer die Zusammenhänge erkennt und voneinander trennen kann, bringt es zu einem robusten Verständnis vom Inhalt eines Bildes. Für Menschen ist das einfach. Wir erkennen etwa eine Tasse auch dann, wenn wir sie aus einer ungewöhnlichen Perspektive oder bei schwierigen Lichtverhältnissen sehen. Und im Gegensatz zu den Machine-Learning-Algorithmen musste dazu niemand uns als Kindern zehn Millionen Bilder von Tassen zeigen.

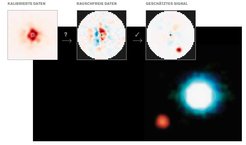
Ähnliche, wenngleich deutlich weniger intuitive Zusammenhänge spielen auch in der Astronomie eine Rolle, etwa bei dem Versuch, mit großen Teleskopen wie dem Very Large Telescope (VLT) in Chile Bilder von Exoplaneten aufzunehmen. Auf deren Aufnahmen ist von den Himmelskörpern in aller Regel nämlich nichts zu sehen. Da die Sterne viel heller leuchten, gehen die Planeten, die sie umkreisen, selbst fast vollständig im Rauschen unter. „Das ist in etwa vergleichbar mit dem Versuch, ein Glühwürmchen an einem mehrere Hundert Kilometer entfernten Leuchtturm zu fotografieren, dessen Scheinwerfer direkt ins Objektiv strahlt“, erklärt Timothy Gebhard. Um diese Aufgabe zu lösen, arbeitet er in der Abteilung für Empirische Inferenz an einem Algorithmus, der kausale Zusammenhänge ausnutzt, um den Aufnahmen des VLT trotzdem Bilder von Exoplaneten zu entlocken.
Um möglichst viele Daten zu sammeln, richten Astronomen ihre Teleskope gleich für mehrere Stunden auf einen Stern, in dessen Umgebung sie einen Planeten vermuten, und nehmen ein Video auf. Darauf ist um den Stern zunächst nur ein Flackern zu sehen, das vor allem durch Turbulenzen in der Erdatmosphäre verursacht wird. Gebhards Aufgabe besteht nun darin, die Tausende Bilder des Videos so zu kombinieren, dass daraus ein einziges Bild entsteht, auf dem der Planet möglichst klar zu erkennen ist. „In der Physik ist man in der luxuriösen Situation, ein gutes Verständnis der kausalen Zusammenhänge des Messvorgangs zu haben“, sagt der Forscher. Im Grunde zählt der Sensor des Teleskops einzelne Lichtteilchen, die vom Planeten selbst oder vom Stern stammen können, und dazu kommt dann noch das Rauschen aus der Atmosphäre und der Messelektronik. Außerdem wandert der Planet im Laufe der Aufnahme auf einer Kreisbahn um seinen Stern. Jedes Pixel enthält also Photonen, die verschiedene Ursachen haben können. „Wir versuchen, unser kausales Wissen über die Entstehung der Daten auszunutzen, um den Aufnahmen die im Rauschen verborgenen Details zu entlocken“, sagt Gebhard. Letztendlich hilft also auch hier das menschliche Gehirn dem künstlichen System beim Erkennen der Kausalitäten auf die Sprünge.
„Über Ursache und Wirkung nachzudenken, bleibt am Menschen hängen“, sagt auch Rüdiger Pryss, Professor für Medizininformatik am Institut für Klinische Epidemiologie und Biometrie der Universität Würzburg. Oft geht es in der Medizin darum, in Patientendaten Muster zu finden, um die Patienten in Gruppen einzuteilen, für die jeweils spezifische Therapien gefunden werden können. Geschieht das mit den gängigen Methoden des maschinellen Lernens, bleibt aber die Frage, warum jemand in einer bestimmten Gruppe gelandet ist, oft unbeantwortet. Die Maschinen können die Gründe für ihre Entscheidungen nicht erklären, und der Mediziner bekommt auch zu wenige Anhaltspunkte, um sie nachvollziehen zu können. Gerade in der Medizin sei es aber unerlässlich, den Menschen an der richtigen Stelle einzubeziehen. Nur er kann den Ergebnissen der Algorithmen Sinn verleihen und muss letztlich auch die daraus abgeleiteten Therapieansätze verantworten. Rüdiger Pryss plädiert also dafür, nicht jedes Problem mit maschinellem Lernen „erschlagen“ zu wollen. „Es gibt sehr mächtige statistische Verfahren, die lange erprobt sind und oft besser zu einem speziellen Anwendungssystem passen“, erklärt der Medizininformatiker. Die seien teils so eindeutig, dass sie das Ursache-Wirkung-Problem weniger aufkommen ließen. Wegen des aktuellen KI-Hypes würden aber viele Anwender instinktiv auf maschinelles Lernen setzen.
Eine gesunde Skepsis gegenüber maschinellem Lernen als vermeintlichem Allheilmittel ist also sicher angebracht. Dennoch wäre es natürlich fahrlässig, ganz auf seine Stärken zu verzichten, vor allem wenn es um das vielleicht dringendste Problem unserer Zeit geht, den Klimawandel. Um auch hier kausale Zusammenhänge berücksichtigen zu können, entwickelt Michel Besserve von der Abteilung für Empirische Inferenz zurzeit einen Algorithmus, der die Effekte von Eingriffen in das globale Wirtschaftssystem automatisch vorhersagen kann. Er soll etwa Politikern in Zukunft dabei helfen, die optimale Strategie zu finden, welche einerseits den Ausstoß von Treibhausgasen minimiert und andererseits möglichst wenige Arbeitsplätze kostet. „Die große Herausforderung dabei ist, dass unser Wirtschaftssystem komplexe Wechselwirkungen zwischen einer Vielzahl von Akteuren mit unterschiedlichen Interessen aufweist“, sagt Besserve. Dabei passt jeder Akteur seine Handlungen an die der anderen an. Will man die Wirtschaft also als kausales Modell beschreiben, treten Kreisläufe auf, in denen sich einzelne Faktoren wechselseitig beeinflussen. „Das daraus resultierende Gleichgewicht zu berechnen, ist wesentlich schwieriger, als wenn die Kausalität immer nur in eine bestimmte Richtung zeigt“, sagt Michel Besserve. Das zugrunde liegende, kausale Modell stammt aus der Ökonomie und beschreibt die Abhängigkeiten und Wechselwirkungen von bis zu 50 unterschiedlichen Sektoren – von Stromerzeugung und Metallverarbeitung über Warentransport bis hin zu Fleischindustrie und Reisanbau. Das ermöglicht es dem Algorithmus, die Veränderungen der Gleichgewichte zu berechnen, die sich ergeben, wenn an einer bestimmten Stelle in das System eingegriffen wird. Dadurch könnten politische Entscheidungsträger bei ihren Überlegungen in Zukunft mehr Variablen berücksichtigen und gleichzeitig unvorhergesehene und unerwünschte Effekte ihrer Eingriffe auf die Wirtschaft vermeiden.
„Die Zeit drängt, und wichtige Entscheidungen müssen jetzt getroffen werden“, sagt Michel Besserve. „Darum ist es auch unser Ziel, das neue Werkzeug möglichst schnell zur Verfügung zu stellen und so mitzuhelfen, eine nachhaltige Ökonomie zu entwickeln.“ Sobald Maschinen also in der Lage sind, mit dem Konzept von Ursache und Wirkung umzugehen, könnten sie auch helfen, die ganz großen Aufgaben der Menschheit zu lösen.
Auf den Punkt gebracht
Algorithmen des maschinellen Lernens trainieren anhand großer Datenmengen, Muster zu erkennen, um etwa aus physiologischen Parametern auf eine Erkrankung zu schließen. Ursache und Wirkung verstehen sie jedoch nicht.
Forschende des Max-Planck-Instituts für Intelligente Systeme wollen Computern ein Verständnis für Kausalitäten beibringen. Anders als etwa Kinder können Algorithmen die entsprechenden Modelle bislang nicht selbst erlernen, sie müssen von Menschen für spezielle Anwendungen entwickelt werden.
Die Max-Planck-Forschenden entwickeln kausale Modelle etwa für eine nachvollziehbare Kreditvergabe, für die Suche nach Exoplaneten oder für die klimapolitische Steuerung eines Wirtschaftssystems.